¿Sabes qué es una base de datos distribuida? ¿Cuáles son sus principales características? ¿Qué ventajas aporta como sistema de almacenamiento de información? En este artículo podrás descubrir la respuestas a estas y muchas otras preguntas.
¿Qué es una base de datos distribuida?
Una base de datos distribuida o BDD consiste en varias bases de datos situadas en diferentes espacios físicos o lógicos, conectadas entre sí por un sistema de comunicaciones.
Las bases de datos distribuidas o Distributed Database Management System (DDBMS) se caracterizan por almacenar la información en varias computadoras conectadas entre sí, a las cuáles el usuarios puede acceder desde cualquier sitio como si se tratara de una red local.
- *Una base de datos de una universidad en la que los ordenadores de Facultades de distintas ciudades están conectados.
- *Un servidor que conecta varias máquinas virtuales.
Características a tener en cuenta
Entre las características de una base de datos distribuida se pueden citar las siguientes:
- Está formada por varias computadoras, a las cuales se les denomina nodos.
- Los nodos se comunican entre sí mediante una red de comunicaciones.
- Cada uno de los ordenadores que forman parte de la red tiene autonomía local.
- Generalmente, la red de computadoras no depende de ningún sitio central.
- Tiene un funcionamiento independiente de su localización.
- Se realizan continuas transacciones de información entre nodos.
- La base de datos funciona independientemente del equipo, sistema operativo o red.
Ventajas y desventajas
Como ya has podido deducir, las bases de datos distribuidas funcionan como una suma de bases de datos individuales conectadas entre sí. Esto les otorga numerosas ventajas, pero también algún inconveniente.
Ventajas
¿Cuáles son las ventajas de una base de datos distribuida?
- Permiten trabajar a cada nodo de la red con autonomía local
- Aumentan la disponibilidad, confiabilidad y eficiencia en el acceso a la información.
- Se pueden expandir de forma indefinida en función de las necesidades de la empresa u organización.
- Permiten la escalabilidad sin necesidad de grandes inversiones.
- Los recursos se comparten entre nodos, de manera que se puede acceder a toda la información desde cualquier sitio.
Desventajas
Por su parte, estas son las desventajas de una base de datos distribuida:
- Resulta más difícil establecer mecanismos para controlar el acceso a los datos y garantizar la seguridad.
- Los errores en la red pueden tener graves consecuencias para la privacidad de la información.
- Es un sistema más complejo de implementar.
- Conseguir una transparencia óptima puede suponer un importante gasto de tiempo y dinero.
- Falta de experiencia y ausencia de estándares en el desarrollo e implementación de estas bases de datos.
- Posibles problemas de rendimiento o fiabilidad derivados del punto anterior.
Niveles de transparencia
Uno de los conceptos básicos en una base de datos distribuida es la transparencia.
La transparencia se entiende como la diferenciación e independencia de los términos de alto nivel de la base de datos, respecto de la semántica de bajo nivel.
Un concepto íntimamente ligado a la transparencia es el de independencia. Las bases de datos distribuidas deben proporcionar independencia de los datos a dos niveles: lógica y física.
- La independencia lógica se define como la capacidad de las aplicaciones de usuario de no verse afectadas por los cambios en la estructura de la base de datos. Es decir, que el usuario pueda seguir usando la base de datos como siempre y no note los cambios en los atributos, relaciones o reordenamientos de la base de datos.
- La independencia física consiste en la capacidad de ocultar al usuario los detalles o estructura del sistema de almacenamiento. Por ejemplo, si los datos se mueven de un nodo a otro.
En relación a esta independencia lógica y física, se pueden hablar de diferentes niveles de transparencia:
- Transparencia a nivel de red: las aplicaciones no deben notar que se accede a los datos a través de una red de computadoras o nodos.
- Transparencia sobre replicación de datos: las réplicas de los objetos de la base de datos no han de ser controladas por el usuario, sino por el propio sistema.
- Transparencia a nivel de fragmentación: el sistema debe ser el encargado de convertir las consultas globales del usuario en consultas definidas sobre fragmentos de la base de datos. Del mismo modo, el sistema también se encarga de mezclar las consultas fragmentadas para obtener la repuesta a una consulta global.
En definitiva, la independencia y la transparencia de los datos son dos conceptos estrechamente relacionados y que resultan claves en el funcionamiento de una base de datos distribuida.
¿Qué es la fragmentación?
La fragmentación en una base de datos distribuida consiste en la partición de una tabla de la base de datos en diferentes fragmentos. Se pueden distinguir dos variantes:
- Fragmentación vertical: la tabla se descompone en columnas (campos)
- Fragmentación horizontal: la tabla se descompone en filas (registros)
Por otro lado, la fragmentación debe cumplir una serie de reglas:
- Regla de completés: los datos contenidos en una relación global han de estar relacionados con algún fragmento.
- Regla de la reconstrucción: a partir de los fragmentos se podrá reconstruir una relación global.
- Regla de los conjuntos disjuntos: los fragmentos no deben compartir ningún elemento en común.
Distribución de los datos
La distribución de la información en estas bases de datos se realiza por medio de transacciones distribuidas.
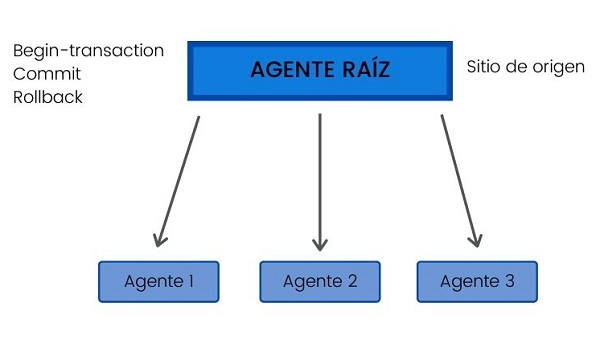
Una transacción distribuida se define como aquella que involucra a varios nodos de una red, a los que se puede llamar agentes. Por tanto, este tipo de transacciones de datos involucran a varios agentes.
Para que se pueda dar una transacción de información en una base de datos distribuida es necesario que los agentes se comuniquen mediante mensajes de red, asegurando que se respeta la atomicidad en el proceso. Para ello se requiere lo siguiente:
- Un agente raíz o sitio de origen de la transacción. Es el que inicia la transacción de datos cuando el usuario ejecuta una aplicación.
- Este agente raíz es también el encargado de garantizar las propiedades de la transacción distribuida, como BEGIN-TRANSACTION, COMMIT O ROLLBACK.
Por otra parte, se puede hablar de diferentes tipos de distribución de los datos. Lo vemos a continuación.
Replicada
El esquema de base de datos distribuida replicada se basa en que cada nodo debe tener una réplica completa de la base de datos. Se trata de un método que supone altos costes para el mantenimiento de la información, ya que cada cambio en una copia debe ser realizada también en todas las demás. Por ello, es un sistema que resulta muy útil en bases de datos en las que se van a hacer pocas tareas de escritura pero muchas de lectura.
Centralizada
En este caso la bases de datos se encuentra centralizada en un lugar concreto físico y lógico, mientras que el resto de clientes están distribuidos. Se basa en el clásico modelo servidor/cliente.
Particionadas
En este caso la información está repartida por los diferentes nodos de la base de datos. Solo existe una copia de cada nodo, pero la información se encuentra dividida en fragmentos disjuntos, cada uno alojado en un sitio o nodo de la base, Al no necesitar realizar copias exactas de toda la información, los costes de almacenamiento son menores. A cambio, se obtiene menor disponibilidad y fiabilidad de los datos.
Híbrida
Es un modelo que combina características de los esquemas de replicación y partición. La mayoría de la información se encuentra particionada, pero hay fragmentos concretos (normalmente los que albergan la información más importante o que más se consulta) que son replicados en los distintos nodos.
Ejemplos
Imaginemos una base de datos que contiene los datos relativos a una Universidad que cuenta con Facultades distribuidas por distintas ciudades. La manera de crear una base de datos común y accesible desde todos los sitios de la Universidad es crear una base de datos distribuida:
- Un nodo de la sede principal donde se almacena la información sobre las diferentes Facultades
- Otros nodos relativos a cada una de las facultades en los que se almacena la información sobre los alumnos.
- Un sistema de red que une todos estos nodos y permite la consulta de la información de forma autónoma.
Empresas que utilizan base de datos distribuidas
Las bases de datos distribuidas se emplean habitualmente en empresas, organizaciones o instituciones que no tienen su actividad centralizada o que, debido a su gran tamaño, requieren la distribución de la información en varios nodos.
Uno de los ejemplos más ilustrativos es Google, la cual tiene alrededor de 20.000 servidores distribuidos en diferentes centrales de datos, a saber, en Washington, Herndon, Santa Clara o Zurich, entre otras.
Otra empresa que ha apostado por una base de datos distribuida es Pepsi.Co., la cual ha desarrollado un sistema con más de 4.000 ordenadores distribuidos en 270 servidores.
Hay muchas más empresas que apuestan por las bases de datos distribuidas, pero la mayoría de ellas tienen en común una característica. son compañías u organizaciones de gran envergadura o que requieren que su información no se encuentre centralizada, debido a que operan en diferentes lugares o al gran volumen de datos que manejan.
En definitiva, las bases de datos distribuidas permiten crear una base de datos global gracias a la unión de diferentes nodos con independencia lógica y física, los cuáles se relacionan entre sí gracias a una red de comunicaciones. Si quieres conocer otros tipos de databases, consulta nuestro artículo principal sobre bases de datos.
Escribe aquí tu comentario