Cualquier empresa u organización actual trabaja con grandes cantidades de datos; datos que necesita almacenar y organizar para su posterior consulta y análisis. Por ello es importante conocer la diferencia entre datos estructurados y datos no estructurados; en esta entrada lo explicamos, junto a ejemplos para ilustrarlos.

¿Qué son datos estructurados?
Para entender mejor las diferencias entre datos estructurados y no estructurados debemos comenzar definirlos primero.
Así, la definición de datos estructurados nos dice que es la información que se encuentra almacenada habitualmente en bases de datos relacionales; los datos estructurados están ordenados en registros (filas) y columnas (atributos), de manera que se estructuran en formato tabla, teniendo un título para cada categoría de datos que permita poder identificarlos. En la mayoría de los casos se trata de archivos de texto.
Los datos estructurales utilizan un lenguaje de programación para gestionarlos, nos referimos al SQL (Estándar Query Language), mediante el cual se pueden hacer consultas a las bases de datos y extraer la información deseada.
Gracias a que están estructurados, son más fáciles de gestionar y permiten una mayor predictibilidad que otros tipos de datos. Esto significa que, además pueden ser procesados fácilmente por cualquier tipo de herramienta de minería de datos.
Son datos estructurados, por ejemplo:
- Hoja de Excel
- Bases de datos relacionales o SQL
- Formularios web
- Fichas de clientes estandarizadas
¿Qué son datos no estructurados?
Los datos no estructurados forman la mayor parte de la información relevante para una empresa u organización. Por lo general, son datos binarios que no tienen una estructura internar identificable. Es decir, sí poseen una estructura interna, pero esta no está sujeta a esquemas o modelos de datos predefinidos, por lo que estamos ante un conjunto desorganizado de varios objetos sin valor hasta que se identifican y se almacenan de manera organizada.
Sin embargo, no se pueden almacenar en una base de datos tradicional, sino que requieren bases de datos no relacionales o NoSQL. Pero una vez organizados en archivos, estos se pueden categorizar para poder obtener información de ellos.
Los datos no estructurados pueden ser textuales o no, además, pueden estar generados tanto por humanos como por máquinas.
Son ejemplos de datos no estructurados:
- Los archivos de imágenes
- Los archivos de audio
- Los PDF
- Los datos de redes sociales
- La mensajería instantánea
- Los datos de geolocalización
Diferencias entre datos estructurados y no estructurados
Como seguro que ya podéis ver, existen diferencias claras entre los datos estructurados y los no estructurados, la más evidente es que no pueden almacenarse en el mismo tipo de base de datos; así, un grupo de datos estructurados son almacenados en un base de datos relacional y un grupo de datos no estructurados se almacenarán en un base de datos no relacional o NoQSL.
También se diferencian en su capacidad de análisis; los datos estructurados, gracias a su estructura organizada, son más fáciles de buscar, consultar y analizar para obtener resultados medibles. Por su parte, aunque los datos no estructurados tienen la capacidad de ofrecer diferentes tipos de información útil, su consulta y análisis resulta mucho más complejo, fundamentalmente porque requieren herramientas analíticas más complejas y que, actualmente, aún no han madurado lo suficiente.
En ese sentido, la información que se puede extraer que el análisis de datos estructurados en Big Data, si bien es un tipo de análisis mucho más extendido, no explota realmente toda la información que pueden arrojar todos los datos que maneja la empresa. Mientras que los datos no estructurados tienen la capacidad de proporcionar una información mucho más completa respecto a los comportamientos e interacciones de los usuarios.
Si miramos la flexibilidad, los datos estructurados son menos flexibles que los no estructurados, lo que implica que estos menos sensibles a los cambios que los primeros. Esto se debe a que al ser almacenados en bruto, el acceso a ellos está, en principio, permitido a cualquier usuario, que puede configurar y reconfigurar la finalidad para la que han concebido dichos datos.
Estas son sus principales diferencias, pero pese a ellas, hay que entender que no son excluyentes, es decir, que si una empresa u organización quiere sacar el mayor partido a la minería y el análisis de datos sus usuarios y usuarios potenciales, debe entender que son conceptos complementarios, que pueden analizarse por separado y después combinarse para aplicar los resultados en la toma de decisiones y diseño de la estrategia de negocio.
Tipos de datos estructurados
Dentro de los datos estructurados encontramos los siguientes tipos:
- Creados: son aquellos que genera la propia empresa u organización para llevar realizar sus análisis de mercado (encuestas a clientes, por ejemplo).
- Provocado: son los datos que provienen de los usuarios, a través de mecanismos que les permitan expresas su valoración.
- Tramitado: son los datos que se recogen de la realización de transacciones completadas (por ejemplo, tramitar el carrito de compra online).
- Compilado: son los datos recogidos del conjunto general de la población (como los censos, los coches matriculados, nivel de estudios, etc.).
- Experimental: estos datos se generan cuando se realizan diferentes acciones de marketing a modo de experimento, para comprobar cuáles son más efectivas. Pueden también provenir de combinar datos creados y transaccionales.
Tipos de datos no estructurados y clasificaciones
Los datos no estructurados se pueden clasificar de la siguiente manera:
- Datos no estructurado y semiestructurados.
- Datos de tipo texto y no texto.
Y dentro de esas clasificaciones tenemos los siguientes tipos:
- Capturados: estos datos son los que se generan de forma pasiva por parte de los usuarios, a través de su conducta (como las búsquedas en Google, la información del GPS o la información biométrica de las smartbands, por ejemplo).
- Generados por el usuario: se trata de los datos que los usuarios generan activamente al navegar por Internet (mensajes en redes sociales, comentarios en publicaciones, vídeos en YouTube, etc.).
Ejemplos de datos estructurados y de no estructurados, en los que se ven claras sus diferencias
A continuación vamos a ver dos ejemplos de datos estructurados y de no estructurados donde las diferencias son visibles.
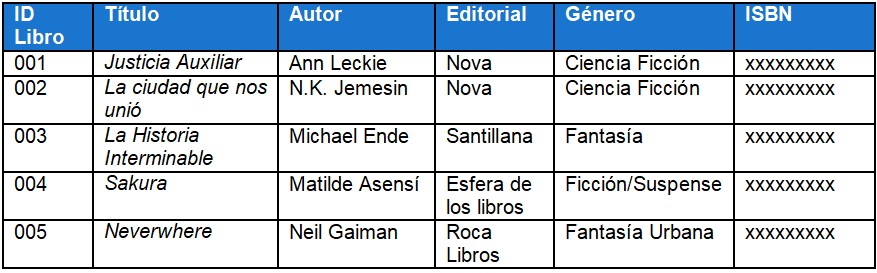
Como veis, en este ejemplo tenemos una tabla que podría adoptar cualquier base de datos de una librería o una biblioteca.
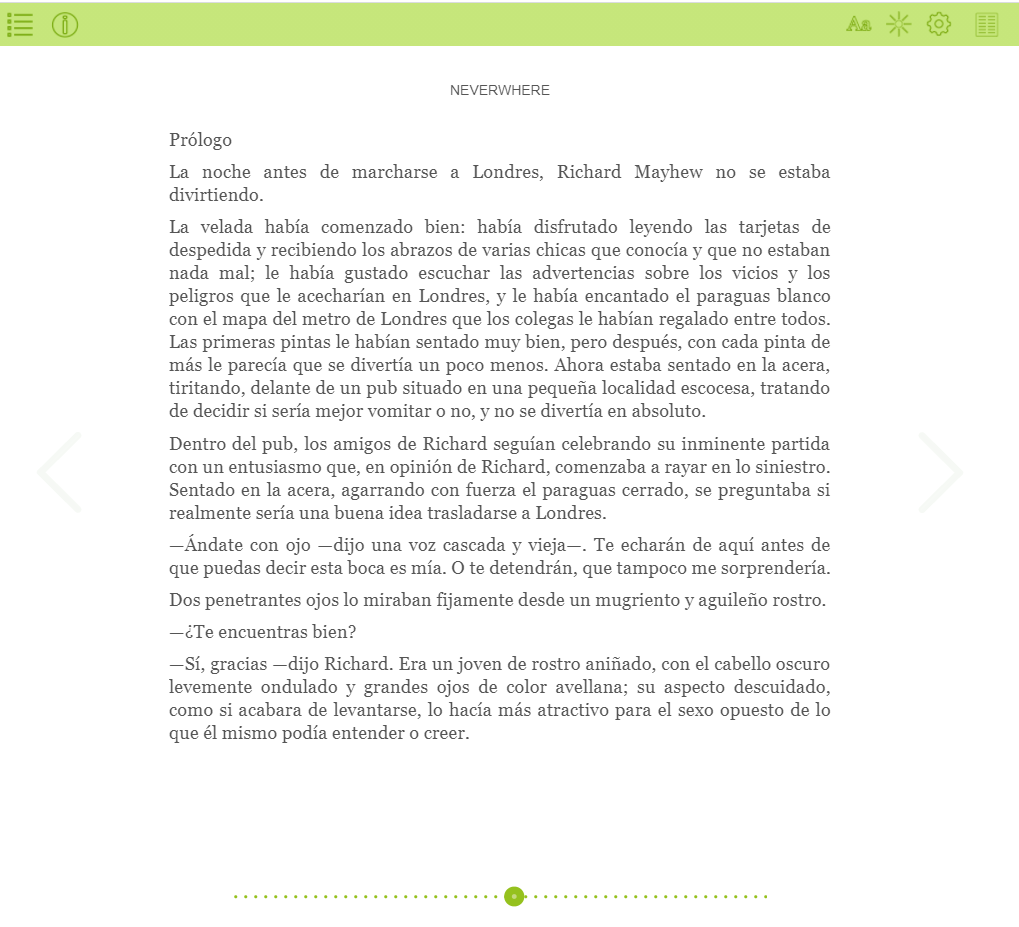
Mientras que en el segundo ejemplo hemos colocado una captura de pantalla en la que podemos ver la primera página del libro Neverwhere, puesto que se trata de un archivo de texto (podría ser el PDF del libro para su lectura en un e-reader) y como tal, se trata de datos no estructurados.
Y los datos semiestructurados ¿Qué son?
Finalmente, existe una última categoría de datos, los datos semiestructurados. Se trata de un punto intermedio entre los datos estructurados y los no estructurados, puesto que los datos semiestructurados tienen cierto nivel de estructura, jerarquía y organización, pero carecen de un esquema fijo, aunque lo habitual es que adopten una forma de árbol para poder manejarlos con más facilidad.
Los datos semiestructurados tienen metadatos, es decir, etiquetas y elementos que se emplean para poder agruparlos y describir cómo almacenarlos, si bien, su gestión y automatización no es tan sencilla como con los datos estructurados.
Así, son ejemplos de datos semiestructuturados:
- Los correos electrónicos.
- El lenguaje XML o cualquier lenguaje de etiquetado o marcado.
- Los ejecutables binarios
Cabe señalar que, aunque el HTML o el JSON se consideran como datos semiestructurados, pueden entenderse como datos estructurados por Google al interpretar el contenido de las páginas a través de ellos. Es decir, se pueden marcar datos estructurados dentro de las páginas a través del uso de etiquetas.
Escribe aquí tu comentario